Online Documentation for SQL Manager for PostgreSQL
Creating/editing aggregate
Use the Aggregate tab of Aggregate Editor to create/edit an aggregate function and specify its definition.
Name
Select a schema and enter a name for the new aggregate, or modify the name of the aggregate being edited.
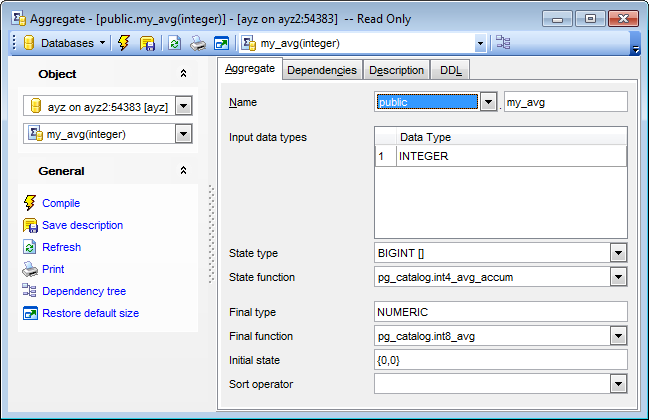
Input data types
Use this area to specify the input data type(s) on which this aggregate function operates. This can be specified as "ANY" for an aggregate that does not examine its input values (an example is count(*)).
State type
Use the drop-down list to select the data type for the aggregate's state value.
State function
Use the drop-down list to select the name of the state transition function to be called for each input data value. This is normally a function of two arguments, the first being of type state data type and the second of type input data type. Alternatively, for an aggregate that does not examine its input values, the function takes just one argument of type state data type. In either case the function must return a value of type state data type. This function takes the current state value and the current input data item, and returns the next state value.
Final type
Specifies the data type for the aggregate's result value.
Final function
Use the drop-down list to select the name of the final function called to compute the aggregate's result after all input data has been traversed. The function must take a single argument of type state data type. The return data type of the aggregate is defined as the return type of this function. If ffunc is not specified, then the ending state value is used as the aggregate's result, and the return type is state data type.
Initial state
Specifies the initial setting for the state value. This must be a string constant in the form accepted for the data type state data type. If not specified, the state value starts out of NULL.
Sort operator
Use the drop-down list to select the sort operator (for a MIN- or MAX-like aggregate).


































































