
Online Documentation for SQL Manager for SQL server
Свойства индекса
На этой вкладке указываются основные параметры индекса.
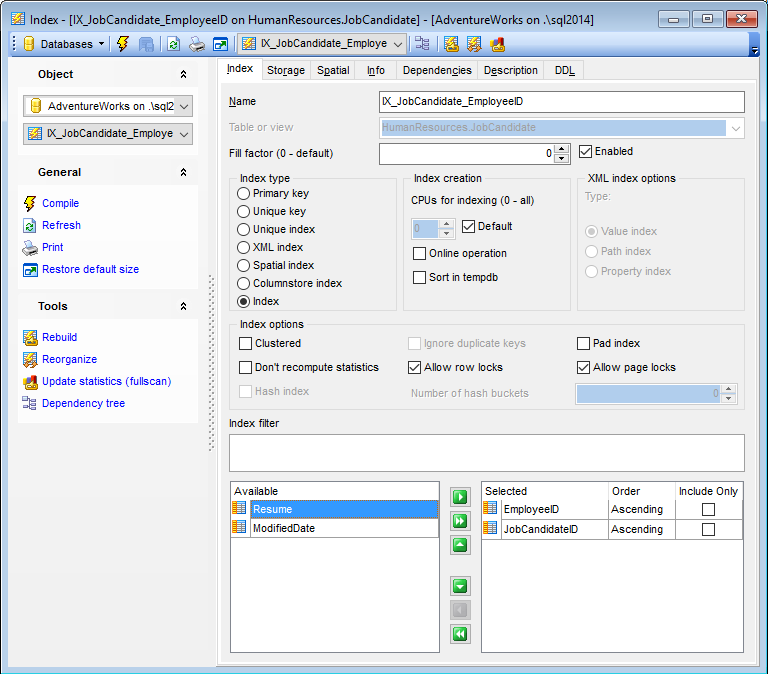
В поле Name укажите имя индекса таблицы.
Из раскрывающегося списка Table выберите таблицу, в которой необходимо создать индекс. (Это поле доступно для изменений только при создании индекса)
С помощью счетчика Fill factor Вы можете задать коэффициент заполнения. Он указывает, насколько полной SQL Server должен сделать каждую страницу при создании нового индекса с помощью существующих данных.
В разделе Index type укажите тип создаваемого индекса:
- Primary Key - выберите это значение если создаете первичный ключ;
- Unique key - если существует уникальный индекс, каждый раз при добавлении данных операциями вставки компонент Database Engine производит проверку на наличие повторяющихся значений. Для операций вставки, которые могли бы сформировать повторяющиеся значения ключей, производится откат, и выводится сообщение об ошибке. Это происходит, даже если операция вставки изменяет несколько строк, а в результате образуется всего одно повторяющееся значение;
- Unique index - создает уникальный индекс для таблицы или представления. Уникальным является индекс, в котором не допускается наличие двух строк с одинаковыми значениями ключа индекса. Кластеризованный индекс представления должен быть уникальным;
- XML index - создает первичный XML-индекс — это разобранное и сохраненное представление XML-объектов BLOB, содержащихся в столбце типа данных xml. Для каждого большого двоичного объекта (BLOB) столбца типа данных xml в индексе создается несколько строк данных, и их количество приблизительно равно числу узлов в большом двоичном объекте XML;
- Spatial index - создает пространственный индекс. Этот индекс используется в пространственных базах данных.
- Columnstore index - Создает индекс columnstore. Такие индексы группируют и сохраняют данные для каждого столбца, затем объединяют все столбцы, чтобы завершить создание всего индекса.
- Index - создает индекс, не задающий ограничения на данные.
Index creation
- Число процессоров, задействованных при выполнении одной индексной инструкции, определяется с помощью счетчика CPUs for indexing (0 - all).
- Online operation. Если установлен этот флажок, то при выполнении операций с индексом в оперативном режиме выполняются следующие правила:
- При выполнении фоновых операций с индексами базовая таблица не может изменяться, усекаться или удаляться.
- Для выполнения операций с индексами необходимо дополнительное временное место на диске.
- Оперативная обработка индексов может выполняться для секционированных индексов, содержащих материализованные вычисляемые или включенные столбцы.
- Sort in tempdb. Если установлен этот флажок, то промежуточные результаты сортировки, которые используются для создания индекса, хранятся в базе данных tempdb.
XML index options (инструменты этого раздела доступны только тогда, когда тип индекса выбран XML index) с помощью этого переключателя выбирается тип вторичного индекса XML:
- Value индекс - если запрос основан на значении, например: /Root/ProductDescription/@*[. = "Mountain Bike"] или //ProductDescription[@Name = "Mountain Bike"], и если путь задан не полностью либо он включает в себя символ-шаблон, скорость выполнения запросов можно повысить, построив вторичный XML-индекс по значениям узлов первичного XML-индекса. Ключевые столбцы индекса VALUE (значение узла и значение пути) содержатся в первичном XML-индексе. Индекс VALUE может оказаться полезным в тех случаях, если рабочая нагрузка включает в себя запросы значений из экземпляров XML, для которых неизвестны имена элементов или атрибутов, содержащих эти значения.
- Path индекс - если обычно запросы задают выражения пути для столбцов типа данных xml, вторичный индекс PATH может ускорить их поиск. Как ранее отмечалось, первичный индекс полезен в тех запросах, где метод exist() указан в предложении WHERE. Добавление вторичного индекса PATH может еще более повысить производительность поиска в таких запросах.
- Property индекс - производительность запросов, извлекающих одно или несколько значений из отдельных экземпляров XML, может повыситься при использовании индекса PROPERTY. Это происходит при извлечении свойств объекта методом value() типа данных xml, когда для объекта известно значение первичного ключа. Индекс PROPERTY строится по столбцам (PK, Path и значении узла) первичного XML-индекса, где PK — это первичный ключ базовой таблицы. Например, для модели продукта 19 следующий запрос извлекает значения атрибутов ProductModelID и ProductModelName при помощи метода value(). Если вместо первичного или вторичных XML-индексов использовать индекс PROPERTY, это может повысить скорость выполнения запросов.
В разделе Index options укажите общие опции индекса.
Установив флажок Clustered, укажите, что индекс кластеризованный. То есть, индекс, в котором физический порядок строк в соответствующей таблице определяется логическим порядком ключевых значений. За некоторыми исключениями, каждая таблица должна иметь кластеризованный индекс. Кроме того, что кластеризованный индекс повышает производительность запросов, его можно перестраивать или переорганизовывать по запросу, управляя фрагментацией таблицы. Кластеризованный индекс может быть также создан для представления.
Если установлен флажок Do not recompute statistics, это значит, что устаревшая статистика не подлежит автоматическому пересчету. Статистические данные устаревают в зависимости от количества операций INSERT, UPDATE и DELETE, выполненных в индексированных столбцах.
Установленный флажок Ignore Duplicate Keys позволяет игнорировать дублирующиеся ключи. Указывает реакцию на ошибку, вызванную дублированием значений ключа в многострочной транзакции INSERT в уникальном кластеризованном или уникальном некластеризованном индексе.
Pad Index - этот флажок устанавливает процентную долю свободного пространства в страницах промежуточного уровня во время создания индекса. Pad Index активен только тогда, когда задан коэффициент заполнения - Fill factor.
Allow row locks определяет, используются ли блокировки строки при доступе к данным индекса.
Allow page lock определяет, используются ли блокировки страницы при доступе к данным индекса.
![]() Hash index (для таблиц, оптимизированнх для памяти)
Hash index (для таблиц, оптимизированнх для памяти)
Отметьте эту опцию, чтобы создать хэшированный индекс. Хэшированный индекс состоит из набора контейнеров, организованных в массив.
Number of hash buckets (для таблиц, оптимизированнх для памяти)
Задайте число контейнеров, которое следует создать в хэшированном индексе.
В поле Index Filter Вы можете задать фильтр для данных полей, содержащихся в индексе. Эта опция доступна только для SQL Server 2008.
В нижней части формы Вы можете выбрать поле из списка имеющихся полей (Available Fields) и поместить его в список выбранных полей-индексов (Selected fields). Делается это с помощью кнопок перетаскивания поля из одного списка в другой или с помощью двойного щелчка мыши.
Удалить поле из списка выбранных можно также с помощью кнопок перетаскивания поля из одного списка в другой или двойного щелчка мыши.
Действия, выполняемые с индексами
Восстановить индексы (REBUILD)
По отношению к индексу будет выполнена команда REBUILD. Это означает, что индекс будет перестроен с использованием тех же столбцов, типов индекса, атрибута уникальности и порядка сортировки.
Реорганизовать индексы (REORGANIZE)
Указывает, что конечный уровень индекса будет реорганизован. Инструкция REORGANIZE всегда выполняется в оперативном режиме. Это означает, что долгосрочные блокировки таблицы не удерживаются и запросы или обновления базовой таблицы могут продолжаться во время выполнения транзакции ALTER INDEX REORGANIZE. Эта операция не может быть выполнена для отключенного индекса.
Обновить статистику (UPDATE STATISTICS FULLSCAN)
Указывает, что все строки в таблице или представлении должны быть считаны, чтобы собрать статистические данные.


































































